之前初见C++的时候总结的string就是C++STL(标准模板库)中的一种容器,现在在有从string的基础上继续深入了解其他STL。
STL的六大组件:容器、算法、迭代器、仿函数、适配器、空间配置器
容器
基础数据结构:数组(array) , 链表(list), 树(tree),栈(stack), 队列(queue), 集合(set),映射表(map)
延申数据结构:字符串(string),向量(vector),可重复集合(multiset),可重复映射表(multiset)、非自动排列集合(unordered_set)、非自动排列映射表(unordered_map)……
也可以按这样分类:序列式容器、关联式容器、无序关联式容器、容器适配器
序列式容器
指按照元素插入的顺序进行存储和访问,可以保持元素的插入顺序并按照顺序进行迭代访问
注意这个和迭代器没有关系,array、vector、deque都是使用随机访问迭代器,可以实现随机访问,而list是使用双向迭代器,forward_list是使用单向迭代器
array
其实就是C++的普通数组,不过添加了一些成员函数和全局函数,比普通数组更安全
对于array的操作,可以沿用C中数组的操作
std::array<double,10> value {0.5,1.0,1.5,2.0};
C中常规数组初始化,剩下的元素为0,可见array元素在初始化的时候已经固定了(官话:元素中未初始化的值不确定)
当然也可以
std::array<double,10> values {}
所有元素初始化为0或者和默认元素类型等效的值
array和一般的STL一样配备了一系列迭代器与成员函数,其中at(n)成员函数返回函数元素值引用,n是下值,此外会检查是否在有效返回内,错误抛出异常,所以说array比普通数组更安全。
一些操作:
max_size()返回容器可容纳的元素最大值,在array中一般和size()一致,不过在vector中会变成一个非常大的值
front()返回第一个值引用
back()返回最后一个值引用
data()返回一个指向容器的指针
fill(val)让容器每个值都变成val
vector
可以理解成大小可变的数组,数组的变化采用特定的成员函数
vector
v1 v1 是一个元素类型为 T 的空 vector vector v2(v1) 使用 v2 中所有元素初始化 v1 vector v2 = v1 同上 vector v3(n, val) v3 中包含了 n 个值为 val 的元素 vector v4(n) v3 中包含了 n 个默认值初始化的元素 vector v5{a, b, c...} 使用 a, b, c... 初始化 v5 vector v1 同上 vector<vector > matrix(M,vector (N)); v.push_back(val)往尾端添加valv.emplace_back(val)往尾端添加val使用大型对象或者代价较高的构造函数时使用
emplace_back()因为这个函数不需要拷贝临时对象,他是直接借助参数的值,在容器中直接创建新对象v.pop_back()删除尾部元素常用以迭代器方式插入、替换、删除类似string
v.sort()以升序排序sort(v.begin(),v.end())
unique()将容器相邻的重复元素消除并返回不重复值范围末尾的迭代器unique(v.begin(),v.end())不会改变原容器大小,消除之后尾部多出来空间不会被删除,所以要手动删除
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(void)
{
vector<int> a{2, 0, 2, 2, 0, 3, 0, 9};
sort(a.begin(), a.end()); // 先排序
for(int i:a) cout << i << " "; // 输出
cout << endl;
auto end_unique = unique(a.begin(), a.end()); //将输入序列相邻的重复项“消除”,返回一个指向不重复值范围末尾的迭代器
a.erase(end_unique, a.end()); // 删除末尾元素
for(int i:a) cout << i << " "; // 输出
return 0;
}
// 运行结果 //
0 0 0 2 2 2 3 9
0 2 3 9
来自CSDN@地球被支点撬走啦
resize(n,t)改变容器大小并赋值为t(新添加)
Vector的扩容
- 完全放弃原有的容器空间
- 创建新的更大的容器空间
- 将原有空间中的数据迁移到新空间
- 将旧空间释放
一般会扩容capasity>=size,在vs中为1.5倍,在linux中为2倍。
空间大小有什么讲究呢?首先不能太大,可能造成空间浪费,也不能太小,太小会导致扩容频繁。
总而言之扩容总是不好的,容易造成运行效率低下,所以避免扩容的方式就是在构造的时候直接进行预估个数大小,或者在插入之前直接进行reserve。
Q1:为什么成倍数扩容?
A1:指定大小扩容时间复杂度为O(n),倍数大小扩容时间复杂度近似O(1)。例如大小10扩容到100,如果指定每次扩容10大小,那么要扩容9次;如果以2倍倍数扩容,则第一次扩容扩到20,第二次扩到40,也就是说扩容之后的算法是以指数形式增长的。
Q2:为什么要是1.5倍?
A2:为了每次扩容的时候能用上原本被释放的空间。vector每次扩容时的机制是找到新的符合要求的内存,还会将原本的空间释放,这个时候如果在多次扩容的时候能用上原本的空间是最好的。例如1空间进行多次扩容,那么会找1.5的新空间,第二次会找2.25的新空间,第三次会找3.375新空间,第四次是5.0625,这个时候会已经释放的空间加起来有4.75,于是再进行几次扩容就可以重复利用之前的空间。如果是两倍则永远都用不上。
list(forward_list为单向链表)
与我们常用的手写链表不同,这是一个双向链表容器
用法和vector差不太多,但底层实现逻辑是双向链表而不是数组
区别和C语言中的链表数组区别差不太多:
存储空间连续与不连续
查找方便与不方便(支不支持随机访问)
添加删除方便与不方便
(额外)可以说vector扩容的时候会拷贝数据,而list不会。
deque
双端队列,基础创建方式仍然和vector类似,顺序性容器
在首部与尾部增添或者删除元素,可以根据需要修改自身的容量和大小,但是不能保证所有的元素都存储在连续的内存空间中。
deque与vector一样支持随机访问,但与vector不同的是存储的内存是分块的,每次新增内存会新增内存块,同样维护了指向这些内存块的指针(第一个和最后一个与当前活跃的)。
- list与deque新增
push_front()
deque的扩容
deque的底层包含map映射区与数据区,首先数据区就是要存数据的数组,其次这个map和后面要说的”关联式容器map“并不是一个东西,虽然名字都是映射。
数据区和vector中的数据区虽然是一个东西,但不一样的是deque中的数据区一般固定为512个字节,这一块”初始“数据区的地址就映射在映射区上,如果需要扩容,就会直接new/malloc新的数据区出来,然后在map上增加地址数据。
deque中含有pfront和ptail两个指针分别指向头和尾,而在初始阶段这两个指针默认指向数据区中心,然后向两边移动。
除此之外,map映射区也得遵循这样的规定,毕竟双端队列deque虽然存储空间有可能不连续,但寻址逻辑一定要是连续的,大致是这样的:
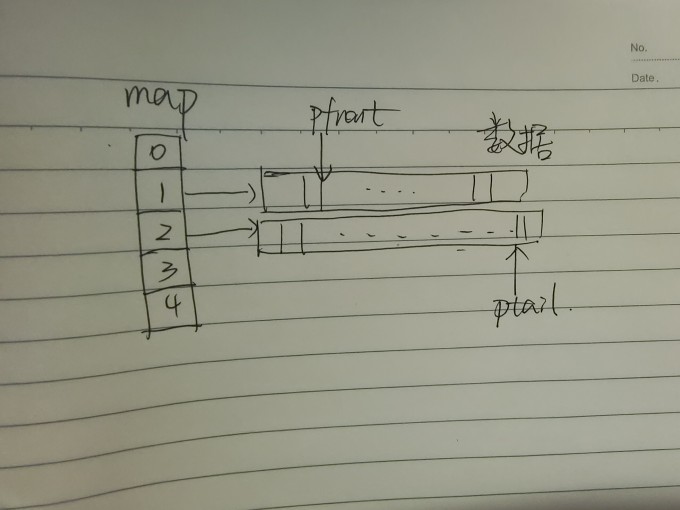
如图map就相当于寻址的”地图“,把不连续的内存段连起来。
那么具体的扩容是怎样扩容的呢?首先deque的扩容不仅是数据段的扩容,还包括map的扩容。
- 当两个指针达到他们当前数据段的极限时,比如pfront到达还要往前第0位,那么就触发扩容,这个时候新增一段数据区是必然的。
- 然后再看map映射区,会先检查映射区里面有没有空间存数据区的地址,比如如果当然数据区地址再映射区是第1位,那么往前就是存进第0位。
- 如果往前没有找到,那么pfront会直接跳到map的尾部,也就是1以及之后的区寻找有没有空间。如果找到了空间,那么整个数据区存在map区的地址就会整体往后移动一个映射区单位,这样第0区就空出来了。这一点对于ptail也是一样的,如果尾部没有就会往前找,总之会先优先寻找已有的空间。
- 如果往前往后都找不到空的map坑位了,这个时候就会触发map映射区的扩容,这个时候map区的扩容是以2倍数扩容的,扩容后01变成0123,并且地址会往中心移动,也就是说现在变成了12位存有地址。
关联式容器
指带有键值的容器,底层由黑红树实现,会根据键值来自动按照某种规矩排序,不能由程序员来改变。
如果说vector封装了数组,list封装了链表,那么关联式容器里运用最广泛的set和map就是封装了二叉树。
Q:为什么说关联式容器插入删除效率比用其他序列容器高?
A:因为关联容器只涉及指针变动,不涉及内存拷贝或者内存移动;此外黑红树的查找效率非常高,这点比顺序性容器中的list优势很多。
Q:关联性容器的数据增添效率问题?
A:这个考虑黑红树树高就能想到了。
初识黑红树 | Coding中。。。 (jiuriri.com)
set
即集合,常见关联式容器中不带Value值的
元素插入时不可重复插入,即集合互异性,并默认按照升序排序。
set的设计目的是唯一性和有序性,其键值不能修改,因为黑红树根据键来排序,如果可以随意更改,那么该元素在黑红树中的位置就会不稳定。
常见的做法是先删除,再添加。
mutliset
多重集合,可以存储相同的集合数据,并且相同的数据数量做Value值
除了可以重复插入,其他性质和set一致。
此外还有unordered_set做无序的集合
unordered_map
无序映射,也就是哈希表的一种实现方式,在算法中常用(也就是说有序映射就是是map,排序规则和set一样)
unordered_map一次性存两个值,一个是key,一个是value,可以通过key来以O(1)的速度查询value,原理是用把key当作哈希函数参数,然后计算出来的地址就是要找的地址,如果发生哈希冲突,则可以通过链地址法或者开放地址法来找新的地址。当然,各种寻找新地址的算法也是一门学问。从效果上看,相当于将普通数组中的(1、2、3...)替换成key值。
另外,使用迭代器时,it->first表示key,it->secend表示value
可以使用std::pair来进行键值插入,也可以使用C++11新引入的花括号进行插入,不过我最常用的还是直接使用下标进行插入。
#include <iostream>
#include <map>
int main() {
std::map<int, std::string> myMap;
// 使用 std::pair 插入元素
myMap.insert(std::pair<int, std::string>(1, "one"));
// 使用花括号初始化列表插入元素
myMap.insert({2, "two"});
//下标插入
myMap[3]="three";
// 打印 map 中的元素
for (const auto& elem : myMap) {
std::cout << elem.first << ": " << elem.second << std::endl;
}
//C++17中的结构化绑定
for (auto [x,y] : myMap) {
std::cout << x << ": " << y << std::endl;
}
return 0;
}
注意multimap由于可以多重关键字,所以不允许用下标访问
容器适配器
对底层容器进行封装,以完成一些特定的需要的功能,比如常见的堆栈队列。
- stack——栈(底层可以是任何迭代器,但默认是deque)
stack<string, vector>这样子就变成vector了
- queue——队列(底层默认也为deque)
- pirority_queue——堆(优先队列,底层默认为vector)
堆基础 | Coding中。。。 (jiuriri.com)
由于使用的实在太多,就不进行详细介绍了,接下来进行知识补充。
队列和双端队列
众所周知队列和栈都是不能遍历的,但双端队列却可以用迭代器遍历,虽然效率很低。
我的理解是队列和栈作为容器适配器是一种规定,如果要遍历,就不要使用他们,或者直接一个个将所有元素pop再重新push进去。而双端队列偏底层,所以一般的操作都是可以的。
迭代器失效问题
除了容器适配器,其他容器都是配置了迭代器的,例如顺序性容器除list之外都是随机访问迭代器,而list本身和关联性容器是双向迭代器。如果在迭代过程中发生了结构变化,那么也就是说这个迭代器过期了,这个迭代器只适用于旧容器。过期的迭代器有可能发生迭代器失效,这样很容易访问到不确定的内容。
迭代器失效的问题大致可以分为以下几类:
- 插入导致失效
- 删除导致失效
- 容器重新分配内存导致失效
- 容器的修改导致失效
所以可以推断在vector中,如果对某结点erase,则当前结点以及之后结点的迭代器失效,因为vector容器位置是相邻的,删除一个元素后面的会挤上来。push_back一个元素,首先end()失效,然后如果没有进行空间分配,则push之前的元素迭代器还有效,如果进行了空间分配,则所有的迭代器都失效。
insert和erase的返回值可以返回下一个迭代器,所以返回给迭代器就行。
vector<int> cont;
for (auto iter = cont.begin(); iter != cont.end();)
{
(*it)->doSomething();
if (shouldDelete(*iter))
iter = cont.erase(iter); //erase删除元素,返回下一个迭代器
else
++iter;
}
deque迭代器首位之外的位置进行插入删除操作就会导致所有迭代器失效,而在首尾进行操作则只会使这两个地方的迭代器失效。
list这种容器只会使被删除的迭代器失效,不会影响其他迭代器,解决方法同样是返回有效迭代器就行。
关联式容器的迭代器原理和list一样,但是区别是erase只会返回void,所以要使用erase(it++)进行迭代,或者直接记录要被删除的结点,在删除之前将迭代器自然迭代在将其删除。