介质访问控制子层
确定多路访问信道下一个使用者的协议,属于数据链路层底部
静态信道分配
这种方法其实就是多路复用技术(FDM),试想一下多个电话用户,但只有一条通话信道,那么FDM的做法就是将其频谱直接平均分为N份(N为用户数量)。当然这是一个很理想的状态,比如说实时通话的人远远少于N,带宽的浪费是难以想象的。
动态信道分配假设
关键假设
流量独立:传输的站都是独立的,独立阻塞
单信道:所有通信都用一个信道
冲突可观察:所有的站都能检测到冲突事件的发生
时间连续或分槽:任何时刻都能开始传输帧/时间分成一段一段,传输只能从某一段开始的时候发生
载波侦听或不听:载波侦听——在传输之前就知道信道时候在被使用
****《多路访问协议》*****
G=每帧平均帧数
ALOHA系统——最好的情况是G=0.5,信道利用率=18%
当用户有数据需要发送时就传输
在ALOHA中,每个站在给中央计算机发送帧之后,中央计算机把帧重新广播给所有站,作为发送者当然能检测到是否能成功。
发生错误时,发送方必须以随机时间在重新发送帧,以避免规律发送从而再次造成冲突。
帧时——指传输一个标准固定长度帧所需要的时间(长度除以比特率)。
很显然,超过两个站在同时发送帧或者还等待其他站帧时过去就再次发帧,就很容易产生冲突。
很遗憾纯ALOHA系统可没法在别人正在发送的时候侦听信道,所以这种冲突很容易发生。
分槽ALOHA——最好的情况是G=1.0,信道利用率=37%
时间分成离散的间隔——时间槽,每个槽对应一帧
使得所有站都必须遵守一个统一的时间槽边界,于是专门有一个特殊的站在每个间隔起始时发出一个脉冲信号。
**《载波侦听多路访问协议》****
站点实际上可以检测其他站点是否在发送数据
在这个协议中,站监听是否存在载波——是否有传输。
坚持和非坚持CSMA
当一个站有数据要发送时,它首先侦 听信道,确定当时是否有其他站正在传输数据;如果信道空闲,它就发送数据。否则,如 果信道忙,该站等待直至信道变成空闲;然后,站发送一帧。
如果发生冲突,该站等待一 段随机的时间,然后再从头开始上述过程。
可以叫做1-坚持,因为发现信道空闲时,传输数据的概率为1
带宽延迟积——如果信道容纳帧很大,带宽延迟积就越大,这样的话侦听信道本身就会产生影响。
非坚持CSMA同样会侦听信道并在其空闲时发送,不同的是,这个协议不会一直监听信道,以至于避免在信道“空闲”那一瞬间马上发出自己的信息——他会自己随机等待一段时间再次监听,可以说是一位不紧不慢的绅士。
p-坚持CSMA适用于分时间槽的信道,当一个站准备好要发送的数据时,它就侦听信道。如果信道是空闲的, 则它按照概率P发送数据。推迟概率q=l-p,将此次发送推迟到下一个时间槽。如果下一 个时间槽信道也是空闲的,则它还是以概率p发送数据,或者以概率q再次推迟发送。这 个过程一直重复,直到帧被发送出去,或者另一个站开始发送数据。
带冲突检测的CSMA
经过上面一系列改进,协议仍然还留下一个硬骨头,那就是极限情况下两个站同时满足能发送的条件,这个冲突几乎无法避免。
冲突检测可以检测到发送冲突时,将传输帧立即“撤回”以节省时间和带宽。
冲突检测的最小时间是将信号传播到另一个站所需要的时间,如果在这段时间内还没检测到冲突,说明信道确实是空闲的,并让其他站知道自己在占用信道。
****《无冲突协议》***
以不可能产生冲突的方式解决信道竞争问题
在这一类协议中N个站被标记成0~N-1
位图协议
每一轮竞争期都含有N个槽,在每一个站要传输数据时,在自己的槽内传输一个信号称为“声明”。N个槽都接收后,每个站点就都知道哪些站要传输数据了,于是按照要传输的数据站的顺序来依次占用信道,这样提前“说好”的方式当然不会产生竞争。——也可以说是“预留协议”
令牌传递
和位图协议很像的方式,令牌从一个预定义的顺序每一个站都传输一次,当存在令牌的站才具有资格传输,如果没有要传输的,则单纯将令牌传输给下一位。
二进制倒计数
如果一个站想要使用信道,就以二进制位串的形式广播自己的地址。
传输协议如下:
假如站0010、0100、1001、1010都想要获得信道,他们都先发送第一位也就是0、0、1、1,那么OR之后为数为1,则前两位退出竞争,因为他们知道有更高位的站参与竞争。以此类推最终的胜者就是1010.
****《有限竞争协议》******
在低负载的情况下采用竞争实现较短延迟,在高负载的情况下采用无冲突技术获得良好的信道效率。
将所有的站分组,几号组的成员才能竞争几号的时间槽,以此减少每个时间槽的竞争“人数”
所以这种协议需要一种将站分配到时间槽的方法
自适应树遍历协议
这种协议很像二叉树的遍历,首先允许所有站进行竞争,如果发生冲突,则只允许某一叶子树进行竞争,以此递推,直到信道成功被某一站占领为止,然后这个槽在运行完毕后会被另一个叶子树竞争。
这种方式用简单的话来说就是“核酸检测混合样本”,如果发生冲突,也i就是说发现样本异常,则取半继续检测,直到找到那个唯一的“阳性”。
**《无线局域网协议》*****
无线电通信。也就是无线局域网。
类似蜂窝电话系统,他们在一定的范围内提供接入服务(AP接入点),但区别是一个“蜂窝”共享一个信道。
无线LAN最大的缺点是每一个接入点——或者说每一个站的覆盖是有一定范围的,而且范围不一定是规律的圆形,这样就容易导致接收站发生冲突,比如ABC站点连成一线,AC相互接收不到而AB与BC能接收到,而无线LAN使用的方法是CSMA,也就是监听是否有其他站在传输,这样导致AC相互听不到,容易造成比如A和C同时向B发送信号造成冲突的情况,容易扰乱信号。
这种”竞争者太远而无法检测潜在的竞争者“,叫做隐藏终端问题。
与此同时也有一个叫暴露终端问题,例如现在是ABCD一条线,B向A发送信息,C本该向D发送信息,结果发现B在发送信息就不发了,这种也是错误的。
冲突避免多路访问(MACA)
同样是拿ABCD举例,现在B向C发送信息,会先发送一个RTS帧,这个短帧包含以后要发送的数据帧长度,然后C回应一个CTS帧,也包含数据长度,A在收到CTS后开始传输。
现在看来,如果有站点接收到RTS而接收不到CTS,意味着它的发送不会影响到接收站,所以在B发送正式帧的时候不受限制——比如A站点;如果有站点接收到CTS(无论是否收到RTS),则必须全程保持沉默。
以太网
IEEE标准协会关键词:
802.3——以太网
802.11——无限局域网
蓝牙——无线PAN
802.15——无限城域网(本章不涉及)
以太网分为经典以太网与交换式以太网,之后会依次讲述到。
二进制指数后退的CSMA/CA
经典以太网使用CSMA/CD,也就是说监听介质到空就立马发送,如果有冲突则等待一段随机时间重新发送。
问题是这个“随机时间”怎么确定。
有一个算法叫二进制指数后退,简单地说就是第一次冲突就在0,1个时间片中选一个等待,第二次就0,1,2,3,第i次就0,.......,2的i次方-1个时间片中随机选一个等待。作用是动态适应发送站的数量。
例子:如果冲突到了1023个时间片里面选,那么两个站几乎不可能冲突;反过来如果让100个站在100个固定的时间片里面一直随机,那发生冲突的次数难以计数
经典以太网与802.11物理层
前者包含多个电缆段和多个中继器,后者使用短程无线电传输信号
经典以太网MAC子层协议
发送帧的方法:CSMA/CD与二进制指数退避算法
然后是是帧格式:
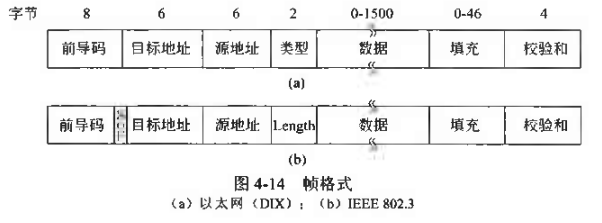
数据段限制帧长度的原因:RAM太贵,限制帧长度也就是限制内存大小;也不能太短,要求帧要和垃圾帧有区分,所以不能小于64字节,期中数据不能小于46字节,太小就填充。还有一个原因是保证往返的时间,因为需要避免错误帧比”警告帧”传播地还快,所以帧长点有助于延缓传播速度。
802.11MAC子层协议
然后是帧格式:
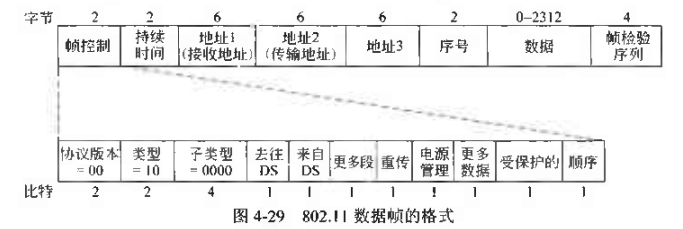
与802.3相比,地址字段为三个,。第一个地址是接收方地址,第二个地址是发送方地址,第三个地址是一个远程端点——其实就是一个中继点
802.16在教材中出现,但我个人就不深入学习了😇
数据链路层交换
网桥:能把多个局域网联结起来组成更大的局域网的设备
路由器:检查数据包的地址,并基于这些地址路由数据包
后向学习算法(backward learing):用来阻止不需要发送的流量
生成树算法(spanning tree):用来打破不管三七二十一把交换机线缆连接起来而可能形成的环路
学习网桥
如果LAN技术是以太网,则网桥就是广为人知的以太网交换机
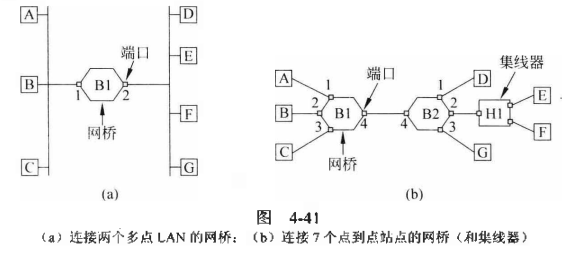
网桥只管与之密切相连的端口,比如说a图,A向B发送帧,B1也会收到,但对于B1看来A向B发送帧对他来说是没什么大不了的事,于是将帧抛弃;如果A向D发送帧,那么必然经过B1,于是B1将帧转发到端口2,再传送到正确的站。
为什么说“只管自己的端口”,可见图b,如果A向D发送帧,那么对于B1来说他要做的就是把帧从端口1转发到端口4,仅此而已。
这些个网桥是怎么知道帧的传送路径的呢?,就好比b中的B1端口是怎么知道转发到4而不是2或3呢?这就涉及到一个算法叫泛洪算法(flooding algorithm),首先所有“与自己相关的端口”,网桥都是通过哈希表储存的,这样一来就可以储存多个站“属于”某端口的信息了,然后哈希表一开始也是空的,在网桥不知道的情况他会直接一口气把所有端口都发个遍(除了发送端),然后必然将正确的那个端口与目的地对应的信息存在哈希表内。
而后向学习法(backward learning)则是用来学习发送端的算法,比如网桥知道发送站点A发送到1端口,那么1端口肯定和A对应。这两个算法也印证了“学习”这两个字。
泛洪算法会不断运行,同样也会有某个特殊进程将“错误出现的信息“剔除,比如某台电脑关机,换了个地方又开机,那么电脑在几分钟之内就会重新回到正常状态。
直通式交换/虫孔路由:帧还没输入完,刚输入地址信息就可以进行转发
生成树网桥
网桥和网桥之间允许冗余多个链路,也就是出现多个目的一致的端口用于增加容错,但前提是解决泛洪算法带来的拓扑环路。
泛洪算法能分辨发送方但分辨不出端口,多个冗余端口会导致信息在两个端口之间不断发送不断”泛洪“
解决方法自然是避免这种拓扑结构出现,有一种思路是”默认拓扑结构的存在,但不承认拓扑结构的存在“——物理上用冗余连接网桥,但实际传输的时候约定好不走某几条路,并让剩下能走的路组成一颗树的形式。这种构造生成树的算法便被标准化为IEEE802.1D。
这种算法需要关注的方面还包括:站点之间的最短路径、路径的最低标识、”忽略“的路径等等。
虚拟局域网WLAN
试想一座大楼,一个大公司共用一个局域网,网络的级别已经远远大于公司不同组织部门级别了。网络当然是相互连接的,但网络管理员有义务将用户分为不同的组,以便完全性与网络负载分配考虑。还有一个原因是网络广播,试想一下泛洪算法在处理大型LAN的时候的流量损失量,网络管理员需要将网络分组以限制这些”广播“所产生的流量。